GPU Driven Voxel Rendering

(Note: This blog post was originally uploaded mid 2022, but due to some data loss issues I have only recently recovered it)
I will outline the process of creating a fully GPU driven pipeline for rendering large amounts of chunks. The tradeoffs I had to make to achieve the goals I had set out. And future work that could be done to increase performance, along with other ideas that could / should be visited.
Disclaimer: The order in which the pipeline is evolved is not the order that was followed in my experience implementing this. I have reordered it to be more coherent / fluent for your reading pleasure
Goals
- Render all voxels in a single draw call
- Fast 144fps+
- Reasonable solution
- Portable
Precursor
This is for a Minecraft like voxel world (literally, I'm getting the data from a Minecraft server)
| term | explanation |
|---|---|
| Chunk Section | 16x16x16 block of blocks |
| Chunk | 16 vertically stacked chunk sections |
| World | A bunch of chunks at different x / z positions |
Initial Attempt
In my initial attempt, I went for a very naive attempt of setting up a vertex buffer, and an index buffer.
Generating vertices and indices
for (auto chunk : chunks) {
for (auto x = 0; x < 16; x++)
for (auto y = 0; y < 256; y++)
for (auto z = 0; z < 16; z++)
{
if (chunk.get_block(x, y, z))
{
auto pos = glm::ivec3(x, y, z);
auto surrounding = std::bitset<6>();
if (pos.z == 0 || !chunk.get_block(x, y, z - 1))
surrounding.set(0);
if (pos.x == 15 || !chunk.get_block(x + 1, y, z))
surrounding.set(1);
if (pos.z == 15 || !chunk.get_block(x, y, z + 1))
surrounding.set(2);
if (pos.x == 0 || !chunk.get_block(x - 1, y, z))
surrounding.set(3);
if (pos.y == 255 || !chunk.get_block(x, y + 1, z))
surrounding.set(4);
if (pos.y == 0 || !chunk.get_block(x, y - 1, z))
surrounding.set(5);
for (auto i = 0; i < surrounding.size(); i++)
if (surrounding[i])
_add_face({chunk.x, chunk.z}, pos, static_cast<block_face>(i));
}
}
}
}
void _add_face(glm::ivec2 chunk, glm::ivec3 block_pos, block_face face)
{
const auto offset = glm::vec3(chunk.x * 16 + block_pos.x, block_pos.y, chunk.y * 16 + block_pos.z);
const auto cube_vertices = std::array<glm::vec3, 8>({
glm::vec3(0, 0, 0) + offset,
glm::vec3(1, 0, 0) + offset,
glm::vec3(1, 1, 0) + offset,
glm::vec3(0, 1, 0) + offset,
glm::vec3(0, 0, 1) + offset,
glm::vec3(1, 0, 1) + offset,
glm::vec3(1, 1, 1) + offset,
glm::vec3(0, 1, 1) + offset
});
auto normal = glm::vec3();
auto indices = std::array<std::uint32_t, 6>();
switch (face)
{
case block_face::north:
indices = { 0, 2, 1, 2, 0, 3 };
normal = glm::vec3(0, 0, -1);
break;
case block_face::east:
indices = { 1, 6, 5, 6, 1, 2 };
normal = glm::vec3(1, 0, 0);
break;
case block_face::south:
indices = { 7, 5, 6, 5, 7, 4 };
normal = glm::vec3(0, 0, 1);
break;
case block_face::west:
indices = { 4, 3, 0, 3, 4, 7 };
normal = glm::vec3(-1, 0, 0);
break;
case block_face::top:
indices = { 3, 6, 2, 6, 3, 7 };
normal = glm::vec3(0, 1, 0);
break;
case block_face::bottom:
indices = { 4, 1, 5, 1, 4, 0 };
normal = glm::vec3(0, -1, 0);
break;
}
for (auto index : indices)
_indices.push_back(index + _vertices.size());
const auto col = glm::vec3(1.0, 1.0, 1.0);
for (auto vert : cube_vertices)
_vertices.push_back(renderer::vertex{
.pos = vert,
.col = col,
.normal = normal
});
}
Code for rendering vertices and indices
void render(auto vao, auto ebo, auto index_count)
{
glBindVertexArray(vao);
glBindBuffer(GL_ELEMENT_ARRAY_BUFFER, ebo);
glDrawElements(GL_TRIANGLES, index_count, GL_UNSIGNED_INT, nullptr);
}
The code above for rendering is ran for every chunk that should be rendered
This method works, but with some problems. It's not very performant, and has N draw calls, where N is amount of chunks to be drawn.
The meshing function also takes 1.3ms after optimisations. (Initially it took 2.6ms), the main thing that the meshing function was spending time in was checking for face visibility, this leads to
Precomputing Visible Faces
Blocks are currently a uint16_t with block ID / meta packed. Caching the visible face would only use 6 bits. Which would give me 10 spare bits for future information.
Code for some methods in the block class
void set_id(uint16_t id) {
_data = (static_cast<uint32_t>(id) << ID_SHIFT) & ID_MASK;
}
[[nodiscard]]
uint16_t id() const noexcept {
return static_cast<uint16_t>((_data & ID_MASK) >> ID_SHIFT);
}
void set_visible(face block_face) noexcept {
_data |= FACE_MASKS[static_cast<uint32_t>(block_face)];
}
void set_unvisible(face block_face) noexcept {
_data &= ~FACE_MASKS[static_cast<uint32_t>(block_face)];
}
[[nodiscard]]
bool visible(face block_face) const noexcept {
return _data & FACE_MASKS[static_cast<uint32_t>(block_face)];
}
Precomputing visible faces made the function a lot faster, down to about 300 microseconds.
for (const auto &it : world._chunks) {
const auto &chunk = it.second;
for (auto x = 0; x < 16; x++)
for (auto y = 0; y < 256; y++)
for (auto z = 0; z < 16; z++)
for (auto i = 0; i < 6; i++)
if (chunk.get_block(x, y, z).visible(static_cast<block_face>(i))
_add_face({chunk.x, chunk.z}, pos, static_cast<block_face>(i));
}
}
}
The next step was moving the code for generating vertices / indices to the GPU.
GPU Vertex / Index Generation
Going to the GPU seemed like an obvious choice, as we have a nested loop that could be replaced by going parallel.
The design choice from this became to create a compute shader where each invocation mapped to a block.
uint cube_verts_size = 0;
vec3 cube_verts[8] = {
vec3(0),
vec3(0),
vec3(0),
vec3(0),
vec3(0),
vec3(0),
vec3(0),
vec3(0),
};
uint cube_indices_size = 0;
int cube_indices[24] = {0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0};
int IDX_LUT[8] = { -1, -1, -1, -1, -1, -1, -1, -1 };
void insert_vertex(uint vert_type) {
if (IDX_LUT[vert_type] == -1)
{
IDX_LUT[vert_type] = int(cube_verts_size);
vec3 vert = CVS[vert_type];
cube_verts[cube_verts_size++] = vert;
}
}
void insert_index(uint index) {
cube_indices[cube_indices_size++] = IDX_LUT[index];
}
void main() {
ivec3 bp = gl_GlobalInvocationID;
uint block = blocks[bp.x][bp.y][bp.z];
bool faces[6];
faces[FF] = bool(block & uint(0x8000));
faces[FB] = bool(block & uint(0x4000));
faces[FL] = bool(block & uint(0x2000));
faces[FR] = bool(block & uint(0x1000));
faces[FT] = bool(block & uint(0x800));
faces[FD] = bool(block & uint(0x400));
if (faces[FD]) {
insert_vertex(IBXX);
insert_vertex(IBXY);
insert_vertex(IBYX);
insert_vertex(IBYY);
insert_index(IBXY);
insert_index(IBXX);
insert_index(IBYX);
insert_index(IBYY);
insert_index(IBXY);
insert_index(IBYX);
}
// A lot more if (faces[FACE]) and inserting vertices / indices
uint current_vertex_size = atomicAdd(vertex_count, cube_verts_size);
for (int i = 0; i < cube_verts_size; i++)
{
vertices[i + current_vertex_size][0] = cube_verts[i].x + gl_LocalInvocationID.x;
vertices[i + current_vertex_size][1] = cube_verts[i].y;
vertices[i + current_vertex_size][2] = cube_verts[i].z;
}
uint current_index = atomicAdd(count, cube_indices_size);
for (int i = 0; i < cube_indices_size; i++)
indices[i + current_index] = cube_indices[i] + current_vertex_size;
Surprisingly enough, this function took just as long on the GPU as the CPU (they were both within the same amount of time to execute). This was due to the driver overhead of dispatching compute invocations for every chunk & global atomic adds left right and centre.
Optimising GPU Vertex / Index Generation
There were 2 major performance bottlenecks
- Driver overhead of dispatching
Ncompute passes, whereNis the amount of chunks to be meshed - Too many global atomic operations
Problem 1 will be addressed later, for now we will focus on 2.
To reduce the amount of global atomics, rethinking how the vertices / indices are written needs to happen. Let's take a look at the current code for writing verticesuint current_vertex_size = atomicAdd(vertex_count, cube_verts_size);
This line of code can be thought of as allocating cube_verts_size vertices, taking the allocation and then writing to it.
Currently this is ran on every compute invocation, this is 65,536 global atomic operations per chunk. When we break down what's happening with that line of code, on all the threads we can see it as something like the following.
Thread 1 - Work Group 1: Hey global atomic, can I get an allocation of size N
Global Atomic: Ok sure here it is
Thread 2 - Work Group 1: Hey global atomic, can I get an allocation of size N
Global Atomic: Ok sure here it is
Thread 3 - Work Group 1: Hey global atomic, can I get an allocation of size N
Global Atomic: Ok sure here it is
Thread 4 - Work Group 1: Hey global atomic, can I get an allocation of size N
Global Atomic: Ok sure here it is
We want to reduce the amount of times the global atomic has to say "Ok sure here it is", we can do this by summing up all of the Ns in the work group, having an elected thread ask the global atomic on behalf of the work group, and then per thread adding both of these allocations to get the index into the buffer.
With this, the conversation will look something like so.
Thread 1 - Work group 1: Hey shared atomic, can I get an allocation of size N
Shared Atomic: Sure here it is
Thread 2 - Work group 1: Hey shared atomic, can I get an allocation of size N
Shared Atomic: Sure here it is
Thread 3 - Work group 1: Hey shared atomic, can I get an allocation of size N
Shared Atomic: Sure here it is
Thread 4 - Work group 1: Hey shared atomic, can I get an allocation of size N
Shared Atomic: Sure here it is
Thread 1 - Work group 1: Hey Global Atomic, can I get an allocation of size N (where N is the value of the shared atomic)
Global Atomic: Yeah sure!
This implementation drastically reduces the amount of global atomic operations that are done. The code for this is also not impossible to understand.
Basic code for a theoretical shader that would write a random number to a buffer
uniform uint global_element_count;
shared uint shared_element_count = 0;
shared uint shared_buffer_index = 0;
buffer number_buffer {
int numbers[];
};
void main() {
int number = generate_random_number(); // Pretend this function exists
bool should_write = number > 1024;
if (should_write)
{
uint group_local_offset = atomicAdd(shared_element_count, 1);
barrier();
if (gl_LocalInvocationIndex == 0) // Elected thread check
shared_buffer_index = atomicAdd(global_element_count, shared_element_count);
barrier();
numbers[group_local_offset + shared_buffer_index] = number;
}
}
After applying this optimisation to generating vertices / indices, meshing chunks went down to ~200 microseconds (Note: this was total time it took to call the function, which would wait for the GPU to finish the compute shader)
At this point I was happy with the speed (Even though it could go faster), and tackled the next problem in quest for fast voxels
Indirect Rendering
As you saw in the previous code, the vertex count is stored in a buffer and then read into the CPU to render. Indirect rendering is a perfect solution for this, you can specify the amount of vertices to render, and make the CPUs job a lot easier.
Implementing it was the following steps
Creating a buffer per chunk with a indirect draw command (for the GPU to update)
struct IndirectDrawCommand {
uint32_t count = 0;
uint32_t instanceCount = 1;
uint32_t firstIndex = 0;
int32_t baseVertex = 0;
uint32_t reservedMustBeZero = 0;
}
Then in the meshing compute shader, I swapped the global uint for vertices for the count member in the IndirectDrawCommand, this was all the work required to make it indirect.
The last simple thing that will happen in this blog post
Bufferless Rendering
At this point, the code was working and I was quite happy with the performance. But it was using quite a lot of GPU memory generating vertices / indices is a waste of space when you know everything that you're rendering is going to be a quad. The solution I choose for this problem was going for bufferless rendering.
Instead of normal vertices / indices, I went for a single buffer per chunk of faces where every face was
ivec4 face;
// X Y Z is block position of quad
// W's first 16 bits are block ID
// W's next 6 bits are direction of the face (else unused)
To know before hand how many faces would be generated, iteration through all chunk sections in the chunk to be rendered is done and visible faces are summed up.
Code for counting visible faces in a chunk
size_t let::chunk_section::visible_faces() const noexcept {
auto faces = size_t(0);
for (auto block : blocks)
for (int i = 0; i < 6; i++)
faces += block.visible(static_cast<block::face>(i));
return faces;
}
And now instead of a vertex and index buffer, we have a single faces buffer
layout(std430, binding = 0) buffer faces_buffer {
ivec4 faces[];
};
And the main function for the compute shader is now
void main() {
uint block = get_block(gl_GlobalInvocationID);
int total_face_count = face_count(block);
uint group_local_offset = atomicAdd(shared_vertex_count, total_face_count * 6) / 6;
barrier();
if (gl_LocalInvocationIndex == 0) {
shared_buffer_index = atomicAdd(indirect.vertex_count, shared_vertex_count) / 6;
}
barrier();
write_faces(shared_buffer_index + group_local_offset, block, bp);
}
The extra * 6 and / 6, is because the code still currently uses the indirect vertex count directly. Given that each face has 6 vertices, this works out quite nicely
The vertex shader also needs to be updated to support generating vertices from faces.
layout(std430, binding = 0) buffer faces_buffer {
ivec4 faces[];
};
uniform ivec2 chunk_pos;
uniform mat4 vp;
out vec3 c_col;
out vec3 c_normal;
void main()
{
int face_idx = gl_VertexID / 6;
int face_vertex_num = gl_VertexID % 6;
ivec4 face = faces[face_idx];
vec3 block_pos = (vec3) face.xyz;
uint direction = get_direction_from_packed(face.w);
uint id = get_id_from_packed(face.w);
uint meta = get_meta_from_packed(face.w);
// These arrays are just look up tables
vec3 pos = CVS[BLOCK_VERTEX_LUT[direction][face_vertex_num]] + block_pos;
vec3 chunk_pos = vec3(positions[gl_DrawID].xyy) * vec3(16.0, 0.0, 16.0);
gl_Position = vp * vec4(pos + chunk_pos, 1.0);
c_normal = NORMAL_LUT[direction];
c_col = vec3(0.2f);
}
Lookup tables
#define ITNNV 0
#define ITNPV 1
#define ITPNV 2
#define ITPPV 3
#define IBNPV 4
#define IBNNV 5
#define IBPPV 6
#define IBPNV 7
vec3 CVS[8] = {
vec3(0, 1, 0),
vec3(0, 1, 1),
vec3(1, 1, 0),
vec3(1, 1, 1),
vec3(0, 0, 0),
vec3(0, 0, 1),
vec3(1, 0, 0),
vec3(1, 0, 1),
};
#define FN 0
#define FS 1
#define FW 2
#define FE 3
#define FU 4
#define FD 5
vec3 NORMAL_LUT[6] = {
vec3( 0, -1, 0),
vec3( 0, 1, 0),
vec3( 0, 0, 1),
vec3( 0, 0, -1),
vec3( 1, 0, 0),
vec3(-1, 0, 0),
};
int BLOCK_VERTEX_LUT[6][6] = {
{IBNNV, IBPNV, ITPPV, ITNPV, IBNNV, ITPPV},
{IBPPV, IBNPV, ITPNV, IBNPV, ITNNV, ITPNV},
{IBPNV, IBPPV, ITPNV, IBPNV, ITPNV, ITPPV},
{IBNPV, IBNNV, ITNNV, ITNNV, IBNNV, ITNPV},
{ITNNV, ITNPV, ITPNV, ITNPV, ITPPV, ITPNV},
{IBNNV, IBNPV, IBPNV, IBNPV, IBPPV, IBPNV}
};
There was no massive speed gain from this, but memory usage was lowered by 4x, which is required for the final boss of rendering voxels fast
Before getting to the final boss, there's a small (but critical) optimisation that needs to be done
Compressing Face data from 16 bytes to 4
Currently, blocks are a ivec4. This can be optimised
Instead of storing the full X / Y / Z, we can store the X Y Z offset from the chunk origin, the values are in the range [0..15], [0..255], [0..15] (respectively, and inclusive)
We can pack that in 16 bits
uint block = 0;
block |= uint((block_pos.x & 0xF) << 28);
block |= uint((block_pos.y & 0xFF) << 20);
block |= uint((block_pos.z & 0xF) << 16);
but we also need which direction the face is, that's 6 values and 3 bits.block |= uint((direction & uint(0x7)) << 13);
And we also need the block id / meta.
block |= uint((block_id & uint(0xFF)) << 5);
block |= uint((block_meta & uint(0xF)) << 1);
Leaving us with 1 bit spare. Now that we've optimised memory usage by 4x, we can move onto the final boss.
1 Call All The Things
At this point, the system is pretty complex / fast. But it can be better, there is still currently N draw calls for N chunks, and N compute dispatches. This is the main bottle neck (Driver overhead).
This can be solved by having 1 draw call for the scene, and 1 compute dispatch for N chunks. Let's go through how doing this is possible, and the tradeoffs I made to support this.
1 Compute Dispatch

Currently, we have 1 buffer per chunk. These buffers are just large enough to store a single chunks data (as we compute how many faces it could be holding maximum) Once the compute shader is dispatched on a chunk, the buffer we allocated looks like so (Where red boxes represent a face)
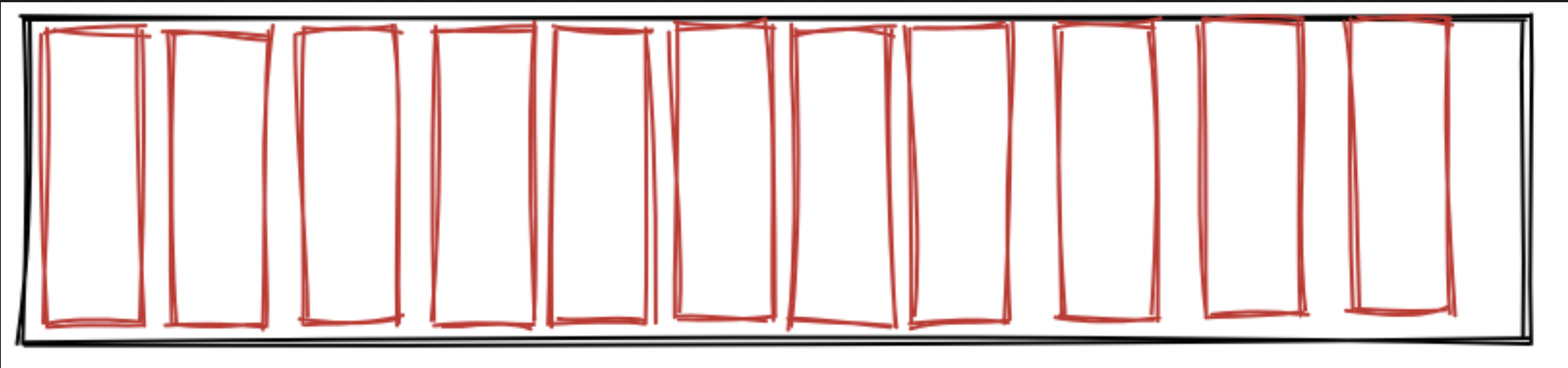
To achieve one compute dispatch, we need a place to put all of our chunks. To solve this problem, a memory usage tradeoff was used. Single chunk "slots" have enough memory to store up to 196608 faces (The maximum a chunk can have). Writing to the chunk slots remains the same, but we essentially have a GPU side std::vector implementation.
To make this tradeoff work for multiple chunks, we allocate a single buffer that can store any N amount of chunks with a worst case of chunks visible. The resulting buffer looks like this

We also need to create a buffer for our indirect commands, as we use those for keeping track of how many faces we have. That ends up looking like this

ivec3 bp = ivec3(gl_GlobalInvocationID);
uint block = get_block(bp);
int total_face_count = face_count(block);
uint group_local_offset = atomicAdd(shared_vertex_count, total_face_count * 6) / 6;
barrier();
if (gl_LocalInvocationIndex == 0) {
uint index = chunk_face_indices[bp.x / 16] / 196608;
shared_buffer_index = atomicAdd(indirects[index].vertex_count, shared_vertex_count) / 6;
}
barrier();
write_faces(shared_buffer_index + group_local_offset + chunk_face_indices[bp.x / 16], block, bp);
With this, generating face data for N chunks in 1 compute dispatch is possible. (And we also happen to get all of the face data in a single buffer... for research purposes)
But now we need to deal with the question, how do we upload more than 1 chunk to the GPU? how do we index into it properly?
For uploading the data to the GPU, I once again use a memory tradeoff.auto block_data = std::vector<uint32_t>(chunks.size() * 16 * 256 * 16);
This is uploaded to the GPU, and the indexing works like so
Note: Drawn in 2D for ease of explanation
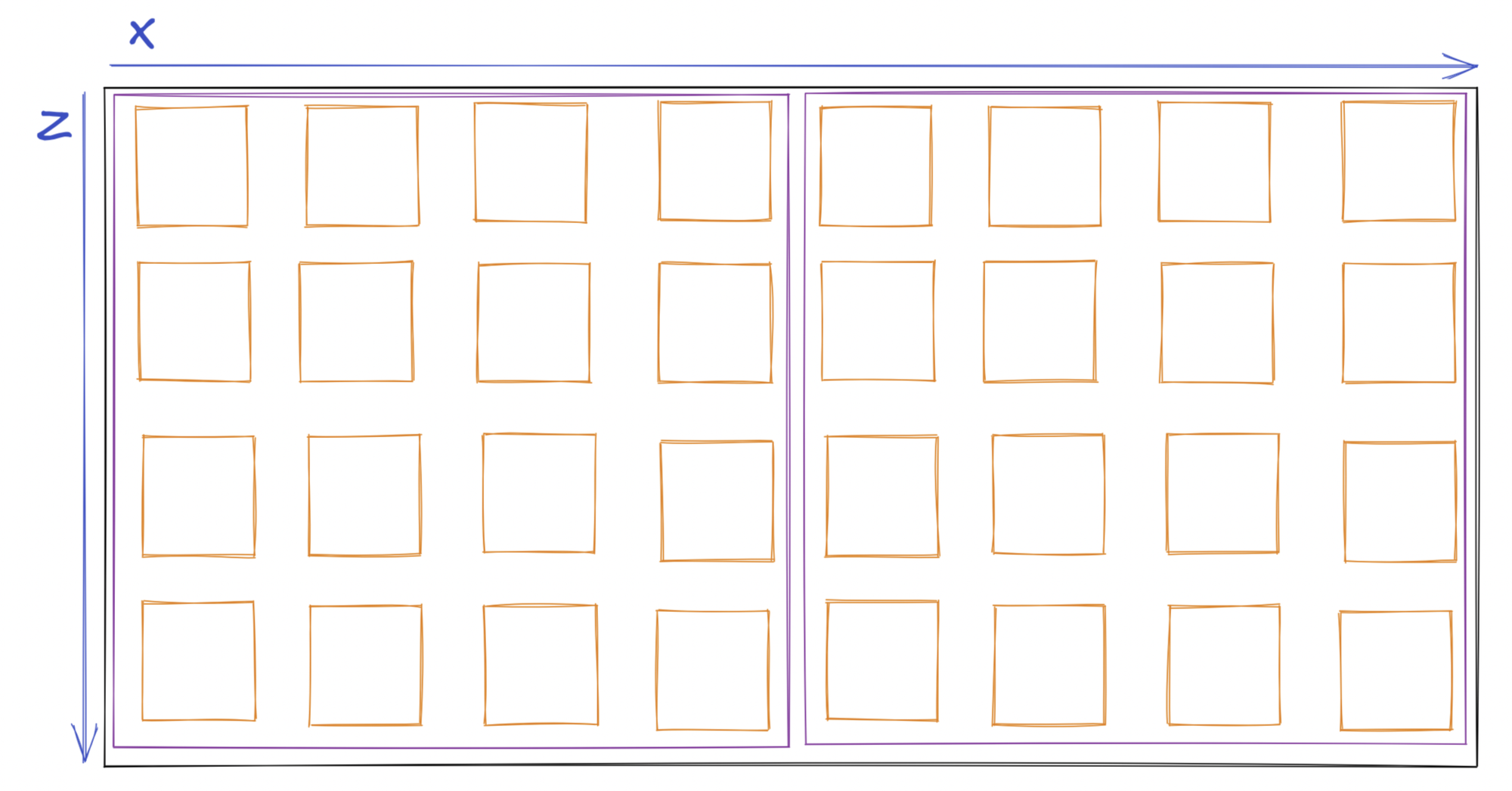
To figure out the index of the chunk we're currently operating on, we divide the gl_GlobalInvocationID.x by the width of the chunk.
uint get_block(ivec3 bp)
{
ivec3 block_pos;
block_pos.x = bp.x % 16;
block_pos.y = bp.y;
block_pos.z = bp.z;
int offset = int(bp.x / 16);
return blocks[(offset * 16 * 256 * 16) + ((block_pos.y & 0xFF) << 8 | (block_pos.z & 0xF) << 4 | (block_pos.x & 0xF))];
}
And now we have a single compute dispatch per frame, if there are any amount of chunks that need to be rendered.
1 Draw Call
Now that we have all of the faces & indirect commands in a single buffer, we can use multi draw to draw all these indirect commands in 1 draw call.
We also need another buffer called positions which stores the positions of chunks based on their index in the faces buffer
glBindBuffer(GL_DRAW_INDIRECT_BUFFER, indirects);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 0, faces);
glBindBufferBase(GL_SHADER_STORAGE_BUFFER, 1, positions);
glMultiDrawArraysIndirect(GL_TRIANGLES, (GLvoid *) 0, chunk_count, 0);
Vertex shader is now updated to this
void main()
{
int face_idx = gl_VertexID / 6;
int face_vertex_num = gl_VertexID % 6;
uint face_data = faces[gl_DrawID * 196608 + face_idx];
vec3 block_pos;
block_pos.x = (face_data >> 28) & uint(0xF);
block_pos.y = (face_data >> 20) & uint(0xFF);
block_pos.z = (face_data >> 16) & uint(0xF);
uint direction = (face_data >> 13) & uint(0x7);
uint id = (face_data >> 5) & uint(0xFF);
uint meta = (face_data >> 1) & uint(0xF);
id = id << 4;
id |= meta & uint(0xF);
uint seed = id;
vec3 pos = CVS[BLOCK_VERTEX_LUT[direction][face_vertex_num]] + block_pos;
vec3 chunk_pos = vec3(positions[gl_DrawID].xyy) * vec3(16.0, 0.0, 16.0);
gl_Position = vp * vec4(pos + chunk_pos, 1.0);
c_normal = NORMAL_LUT[direction];
c_col = vec3(0.2f);
}
And with that, we have a fully GPU driven voxel rendering system.
Now for some performance numbers :)
Note: These numbers are on an "average" Minecraft world with regular overworked terrain, it will be different depending on the terrain. These numbers should be used for a ballpark estimate of performance
GTX1080:
- Meshing takes 17us per chunk
- Rendering takes .84us per chunk
Future work
- Splitting chunk faces into 6 internal indirects, one for each direction and applying a compute shader to write the amount of vertices to write based on the direction the player is looking, to efficiently cull out a lot of unseen blocks
- A system for doing non voxel blocks using the same buffer so 1 draw call can be kept
- Lowering the memory usage by dynamically changing the buffer size